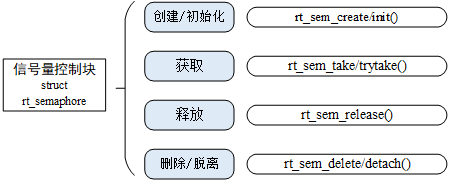
rt_err_trt_sem_take(rt_sem_t sem, rt_int32_t time);
在调用这个函数时,如果信号量的值等于零,那么说明当前信号量资源实例不可用,申请该信号量的线程将根据 time 参数的情况选择直接返回、或挂起等待一段时间、或永久等待,直到其他线程或中断释放该信号量。如果在参数 time 指定的时间内依然得不到信号量,线程将超时返回,返回值是 - RT_ETIMEOUT。下表描述了该函数的输入参数与返回值:
\ | / - RT - Thread Operating System / | \ 4.1.1 build Sep 2202414:52:06 2006 - 2022 Copyright by RT-Thread team msh >semaphore_sample create done. dynamic semaphore value = 0. msh >thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 1 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 2 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 3 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 4 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 5 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 6 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 7 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 8 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 9 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 10 thread1 exiting... thread2 exiting...
msh >semaphore_sample create done. dynamic semaphore value = 0. msh >thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 1 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 2 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 3 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 4 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 5 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 6 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 7 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 8 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 9 thread1 release a dynamic semaphore. thread2 take a dynamic semaphore. number = 10 thread1 exiting... thread2 exiting...
\ | / - RT - Thread Operating System / | \ 4.1.1 build Sep 2 2024 18:24:30 2006 - 2022 Copyright by RT-Thread team msh >producer_consumer the producer generates a number: 1 the consumer[0] get a number: 1 msh >the producer generates a number: 2 the producer generates a number: 3 the consumer[1] get a number: 2 the producer generates a number: 4 the producer generates a number: 5 the consumer[2] get a number: 3 the producer generates a number: 6 the producer generates a number: 7 the producer generates a number: 8 the consumer[3] get a number: 4 the producer generates a number: 9 the consumer[4] get a number: 5 the producer generates a number: 10 the producer exit! the consumer[0] get a number: 6 the consumer[1] get a number: 7 the consumer[2] get a number: 8 the consumer[3] get a number: 9 the consumer[4] get a number: 10 the consumer sum is: 55 the consumer exit!
msh >producer_consumer the producer generates a number: 1 the consumer[0] get a number: 1 msh >the producer generates a number: 2 the producer generates a number: 3 the consumer[1] get a number: 2 the producer generates a number: 4 the producer generates a number: 5 the consumer[2] get a number: 3 the producer generates a number: 6 the producer generates a number: 7 the producer generates a number: 8 the consumer[3] get a number: 4 the producer generates a number: 9 the consumer[4] get a number: 5 the producer generates a number: 10 the producer exit! the consumer[0] get a number: 6 the consumer[1] get a number: 7 the consumer[2] get a number: 8 the consumer[3] get a number: 9 the consumer[4] get a number: 10 the consumer sum is: 55 the consumer exit!
本例程可以理解为生产者生产产品放入仓库,消费者从仓库中取走产品。
(1)生产者线程:
1)获取 1 个空位(放产品 number),此时空位减 1;
2)上锁保护;本次的产生的 number 值为 cnt+1,把值循环存入数组 array 中;再开锁;
3)释放 1 个满位(给仓库中放置一个产品,仓库就多一个满位),满位加 1;
(2)消费者线程:
1)获取 1 个满位(取产品 number),此时满位减 1;
2)上锁保护;将本次生产者生产的 number 值从 array 中读出来,并与上次的 number 值相加;再开锁;
3)释放 1 个空位(从仓库上取走一个产品,仓库就多一个空位),空位加 1。
生产者依次产生 10 个 number,消费者依次取走,并将 10 个 number 的值求和。信号量锁 lock 保护 array 临界区资源:保证了消费者每次取 number 值的排他性,实现了线程间同步。
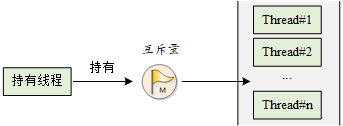
使用信号量会导致的另一个潜在问题是线程优先级翻转问题。所谓优先级翻转,即当一个高优先级线程试图通过信号量机制访问共享资源时,如果该信号量已被一低优先级线程持有,而这个低优先级线程在运行过程中可能又被其它一些中等优先级的线程抢占,因此造成高优先级线程被许多具有较低优先级的线程阻塞,实时性难以得到保证。如下图所示:有优先级为 A、B 和 C 的三个线程,优先级 A> B > C。线程 A,B 处于挂起状态,等待某一事件触发,线程 C 正在运行,此时线程 C 开始使用某一共享资源 M。在使用过程中,线程 A 等待的事件到来,线程 A 转为就绪态,因为它比线程 C 优先级高,所以立即执行。但是当线程 A 要使用共享资源 M 时,由于其正在被线程 C 使用,因此线程 A 被挂起切换到线程 C 运行。如果此时线程 B 等待的事件到来,则线程 B 转为就绪态。由于线程 B 的优先级比线程 C 高,且线程B没有用到共享资源 M ,因此线程 B 开始运行,直到其运行完毕,线程 C 才开始运行。只有当线程 C 释放共享资源 M 后,线程 A 才得以执行。在这种情况下,优先级发生了翻转:线程 B 先于线程 A 运行。这样便不能保证高优先级线程的响应时间。
在 RT-Thread 操作系统中,互斥量可以解决优先级翻转问题,实现的是优先级继承协议 (Sha, 1990)。优先级继承是通过在线程 A 尝试获取共享资源而被挂起的期间内,将线程 C 的优先级提升到线程 A 的优先级别,从而解决优先级翻转引起的问题。这样能够防止 C(间接地防止 A)被 B 抢占,如下图所示。优先级继承是指,提高某个占有某种资源的低优先级线程的优先级,使之与所有等待该资源的线程中优先级最高的那个线程的优先级相等,然后执行,而当这个低优先级线程释放该资源时,优先级重新回到初始设定。因此,继承优先级的线程避免了系统资源被任何中间优先级的线程抢占。
\ | / - RT - Thread Operating System / | \ 3.1.0 build Aug 27 2018 2006 - 2018 Copyright by rt-thread team msh >pri_inversion the priority of thread2 is: 10 the priority of thread3 is: 11 the priority of thread2 is: 10 the priority of thread3 is: 10 test OK.
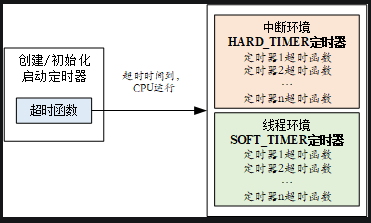
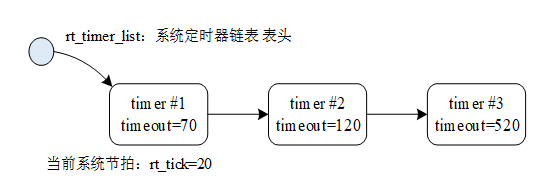
\ | / - RT - Thread Operating System / | \ 3.1.0 build Aug 24 2018 2006 - 2018 Copyright by rt-thread team msh >timer_static_sample msh >periodic timer is timeout periodic timer is timeout one shot timer is timeout periodic timer is timeout periodic timer is timeout periodic timer is timeout periodic timer is timeout periodic timer is timeout periodic timer is timeout periodic timer is timeout periodic timer is timeout
这里将 r 的生命周期标记为 'a 并将 x 的生命周期标记为 'b。如你所见,内部的 'b 块要比外部的生命周期 'a 小得多。在编译时,Rust 比较这两个生命周期的大小,并发现 r 拥有生命周期 'a,不过它引用了一个拥有生命周期 'b 的对象。程序被拒绝编译,因为生命周期 'b 比生命周期 'a 要小:被引用的对象比它的引用者存在的时间更短。
error[E0106]: missing lifetime specifier --> src/main.rs:1:33 | 1 | fn longest(x: &str, y: &str) -> &str { | ^ expected lifetime parameter | = help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
提示文本揭示了返回值需要一个泛型生命周期参数,因为 Rust 并不知道将要返回的引用是指向 x 或 y。事实上我们也不知道,因为函数体中 if 块返回一个 x 的引用而 else 块返回一个 y 的引用!
当我们定义这个函数的时候,并不知道传递给函数的具体值,所以也不知道到底是 if 还是 else 会被执行。我们也不知道传入的引用的具体生命周期,所以也就不能像示例 10-18 和 10-19 那样通过观察作用域来确定返回的引用是否总是有效。借用检查器自身同样也无法确定,因为它不知道 x 和 y 的生命周期是如何与返回值的生命周期相关联的。为了修复这个错误,我们将增加泛型生命周期参数来定义引用间的关系以便借用检查器可以进行分析。
单个生命周期标注本身没有多少意义,因为生命周期标注告诉 Rust 多个引用的泛型生命周期参数如何相互联系的。例如如果函数有一个生命周期 'a 的 i32 的引用的参数 first。还有另一个同样是生命周期 'a 的 i32 的引用的参数 second。这两个生命周期标注意味着引用 first 和 second 必须与这泛型生命周期存在得一样久。
现在来看看 longest 函数的上下文中的生命周期。就像泛型类型参数,泛型生命周期参数需要声明在函数名和参数列表间的尖括号中。这里我们想要告诉 Rust 关于参数中的引用和返回值之间的限制是他们都必须拥有相同的生命周期,就像示例 10-22 中在每个引用中都加上了 'a 那样:
文件名: src/main.rs
1 2 3 4 5 6 7
fnlongest<'a>(x: &'astr, y: &'astr) -> &'astr { if x.len() > y.len() { x } else { y } }
示例 10-22:longest 函数定义指定了签名中所有的引用必须有相同的生命周期 'a
这段代码能够编译并会产生我们希望得到的示例 10-20 中的 main 函数的结果。
现在函数签名表明对于某些生命周期 'a,函数会获取两个参数,他们都是与生命周期 'a 存在的一样长的字符串 slice。函数会返回一个同样也与生命周期 'a 存在的一样长的字符串 slice。它的实际含义是 longest 函数返回的引用的生命周期与传入该函数的引用的生命周期的较小者一致。这就是我们告诉 Rust 需要其保证的约束条件。记住通过在函数签名中指定生命周期参数时,我们并没有改变任何传入值或返回值的生命周期,而是指出任何不满足这个约束条件的值都将被借用检查器拒绝。注意 longest 函数并不需要知道 x 和 y 具体会存在多久,而只需要知道有某个可以被 'a 替代的作用域将会满足这个签名。
当具体的引用被传递给 longest 时,被 'a 所替代的具体生命周期是 x 的作用域与 y 的作用域相重叠的那一部分。换一种说法就是泛型生命周期 'a 的具体生命周期等同于 x 和 y 的生命周期中较小的那一个。因为我们用相同的生命周期参数 'a 标注了返回的引用值,所以返回的引用值就能保证在 x 和 y 中较短的那个生命周期结束之前保持有效。
在这个例子中,string1 直到外部作用域结束都是有效的,string2 则在内部作用域中是有效的,而 result 则引用了一些直到内部作用域结束都是有效的值。借用检查器认可这些代码;它能够编译和运行,并打印出 The longest string is long string is long。
接下来,让我们尝试另外一个例子,该例子揭示了 result 的引用的生命周期必须是两个参数中较短的那个。以下代码将 result 变量的声明移动出内部作用域,但是将 result 和 string2 变量的赋值语句一同留在内部作用域中。接着,使用了变量 result 的 println! 也被移动到内部作用域之外。注意示例 10-24 中的代码不能通过编译:
文件名: src/main.rs
1 2 3 4 5 6 7 8 9
fnmain() { letstring1 = String::from("long string is long"); letresult; { letstring2 = String::from("xyz"); result = longest(string1.as_str(), string2.as_str()); } println!("The longest string is {}", result); }
示例 10-24:尝试在 string2 离开作用域之后使用 result
如果尝试编译会出现如下错误:
1 2 3 4 5 6 7 8 9
error[E0597]: `string2` does not live long enough --> src/main.rs:6:44 | 6 | result = longest(string1.as_str(), string2.as_str()); | ^^^^^^^ borrowed value does not live long enough 7 | } | - `string2` dropped here while still borrowed 8 | println!("The longest string is {}", result); | ------ borrow later used here
错误表明为了保证 println! 中的 result 是有效的,string2 需要直到外部作用域结束都是有效的。Rust 知道这些是因为(longest)函数的参数和返回值都使用了相同的生命周期参数 'a。
error[E0597]: `result` does not live long enough --> src/main.rs:3:5 | 3 | result.as_str() | ^^^^^^ does not live long enough 4 | } | - borrowed value only lives until here | note: borrowed value must be valid for the lifetime 'a as defined on the function body at 1:1... --> src/main.rs:1:1 | 1 | / fn longest<'a>(x: &str, y: &str) -> &'a str { 2 | | let result = String::from("really long string"); 3 | | result.as_str() 4 | | } | |_^
出现的问题是 result 在 longest 函数的结尾将离开作用域并被清理,而我们尝试从函数返回一个 result 的引用。无法指定生命周期参数来改变悬垂引用,而且 Rust 也不允许我们创建一个悬垂引用。在这种情况,最好的解决方案是返回一个有所有权的数据类型而不是一个引用,这样函数调用者就需要负责清理这个值了。
fnmain() { letnovel = String::from("Call me Ishmael. Some years ago..."); letfirst_sentence = novel.split('.') .next() .expect("Could not find a '.'"); leti = ImportantExcerpt { part: first_sentence }; }
示例 10-25:一个存放引用的结构体,所以其定义需要生命周期标注
这个结构体有一个字段,part,它存放了一个字符串 slice,这是一个引用。类似于泛型参数类型,必须在结构体名称后面的尖括号中声明泛型生命周期参数,以便在结构体定义中使用生命周期参数。这个标注意味着 ImportantExcerpt 的实例不能比其 part 字段中的引用存在的更久。
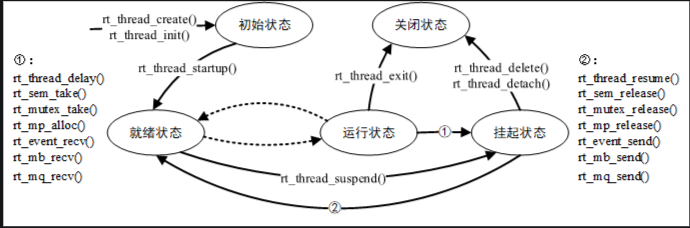
voidthread_entry(void* paramenter) { while (1) { /* 等待事件的发生 */
/* 对事件进行服务、进行处理 */ } }
线程看似没有什么限制程序执行的因素,似乎所有的操作都可以执行。但是作为一个实时系统,一个优先级明确的实时系统,如果一个线程中的程序陷入了死循环操作,那么比它优先级低的线程都将不能够得到执行。所以在实时操作系统中必须注意的一点就是:线程中不能陷入死循环操作,**必须要有让出 CPU 使用权的动作,如循环中调用延时函数或者主动挂起。**用户设计这种无限循环的线程的目的,就是为了让这个线程一直被系统循环调度运行,永不删除。
letarticle = NewsArticle { headline: String::from("Penguins win the Stanley Cup Championship!"), location: String::from("Pittsburgh, PA, USA"), author: String::from("Iceburgh"), content: String::from("The Pittsburgh Penguins once again are the best hockey team in the NHL."), };
解决方案一(简单粗暴): 给 T 再加上 Copy 的 trait bound。这样就限制了 largest 只能用于那些可以简单复制的类型。
1 2 3 4 5 6 7 8 9
fnlargest<T: PartialOrd + Copy>(list: &[T]) -> T { letmut largest = list[0]; // 现在 T 保证是 Copy 的 for &item in list.iter() { // 现在 &item 可以拷贝一份 if item > largest { largest = item; } } largest }
解决方案二(更通用但可能慢): 如果不想限制 Copy,可以要求 T 实现 Clone,然后在需要的时候显式地克隆数据。但这可能会涉及堆内存分配,效率较低。
letresult = largest(&number_list); println!("The largest number is {}", result);
letchar_list = vec!['y', 'm', 'a', 'q'];
letresult = largest(&char_list); println!("The largest char is {}", result); }
示例 10-5:一个使用泛型参数的 largest 函数定义,尚不能编译
如果现在就编译这个代码,会出现如下错误:
1 2 3 4 5 6 7
error[E0369]: binary operation `>` cannot be applied to type `T` --> src/main.rs:5:12 | 5 | if item > largest { | ^^^^^^^^^^^^^^ | = note: an implementation of `std::cmp::PartialOrd` might be missing for `T`
注释中提到了 std::cmp::PartialOrd,这是一个 trait。下一部分会讲到 trait。不过简单来说,这个错误表明 largest 的函数体不能适用于 T 的所有可能的类型。因为在函数体需要比较 T 类型的值,不过它只能用于我们知道如何排序的类型。为了开启比较功能,标准库中定义的 std::cmp::PartialOrd trait 可以实现类型的比较功能(查看附录 C 获取该 trait 的更多信息)。
在这个例子中,当把整型值 5 赋值给 x 时,就告诉了编译器这个 Point<T> 实例中的泛型 T 是整型的。接着指定 y 为 4.0,它被定义为与 x 相同类型,就会得到一个像这样的类型不匹配错误:
1 2 3 4 5 6 7 8 9
error[E0308]: mismatched types --> src/main.rs:7:38 | 7 | let wont_work = Point { x: 5, y: 4.0 }; | ^^^ expected integer, found floating-point number | = note: expected type `{integer}` found type `{float}`
如果想要定义一个 x 和 y 可以有不同类型且仍然是泛型的 Point 结构体,我们可以使用多个泛型类型参数。在示例 10-8 中,我们修改 Point 的定义为拥有两个泛型类型 T 和 U。其中字段 x 是 T 类型的,而字段 y 是 U 类型的:
文件名: src/main.rs
1 2 3 4 5 6 7 8 9 10
structPoint<T, U> { x: T, y: U, }
fnmain() { letboth_integer = Point { x: 5, y: 10 }; letboth_float = Point { x: 1.0, y: 4.0 }; letinteger_and_float = Point { x: 5, y: 4.0 }; }
示例 10-8:使用两个泛型的 Point,这样 x 和 y 可能是不同类型
现在所有的 Point 实例都合法了!你可以在定义中使用任意多的泛型类型参数,不过太多的话,代码将难以阅读和理解。当你的代码中需要许多泛型类型时,它可能表明你的代码需要重构,分解成更小的结构。
现在这个定义应该更容易理解了。如你所见 Option<T> 是一个拥有泛型 T 的枚举,它有两个成员:Some,它存放了一个类型 T 的值,和不存在任何值的 None。通过 Option<T> 枚举可以表达有一个可能的值的抽象概念,同时因为 Option<T> 是泛型的,无论这个可能的值是什么类型都可以使用这个抽象。
枚举也可以拥有多个泛型类型。第 9 章使用过的 Result 枚举定义就是一个这样的例子:
1 2 3 4
enumResult<T, E> { Ok(T), Err(E), }
Result 枚举有两个泛型类型,T 和 E。Result 有两个成员:Ok,它存放一个类型 T 的值,而 Err 则存放一个类型 E 的值。这个定义使得 Result 枚举能很方便的表达任何可能成功(返回 T 类型的值)也可能失败(返回 E 类型的值)的操作。实际上,这就是我们在示例 9-3 用来打开文件的方式:当成功打开文件的时候,T 对应的是 std::fs::File 类型;而当打开文件出现问题时,E 的值则是 std::io::Error 类型。
结构体定义中的泛型类型参数并不总是与结构体方法签名中使用的泛型是同一类型。示例 10-11 中在示例 10-8 中的结构体 Point<T, U> 上定义了一个方法 mixup。这个方法获取另一个 Point 作为参数,而它可能与调用 mixup 的 self 是不同的 Point 类型。这个方法用 self 的 Point 类型的 x 值(类型 T)和参数的 Point 类型的 y 值(类型 W)来创建一个新 Point 类型的实例: